
说明:
下面的图来自南京大学计算机系黄宜华老师开设的mapreduce课程的课件,这里稍作整理和 总结。
本文旨在对接触了mapreduce之后,但是对mapreduce的工作流程仍不是很清楚的人员,当然包括博主自己,希望与大家一起学习。
mapreduce的原理
MapReduce借鉴了函数式程序设计语言Lisp中的思想,Lisp(List processing)是一种列表处理语言,可对列表元素进行整体处理。
如:(add #(1 2 3 4) #(4 3 2 1)) 将产生结果:#(5 5 5 5)
mapreduce之所以和lisp类似,是因为mapreduce在最后的 reduce阶段也是以key为分组进行列的运算。
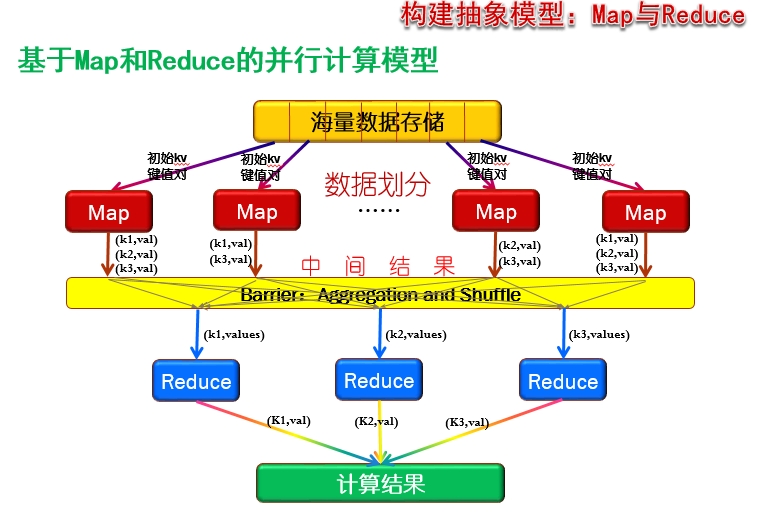
下面这幅图就是mapreduce的工作原理
1)首先文档的数据记录(如文本中的行,或数据表格中的行)是以“键值对”的形式传入map 函数,然后map函数对这些键值对进行处理(如统计词频),然后输出到中间结果。
2)在键值对进入reduce进行处理之前,必须等到所有的map函数都做完,所以既为了达到这种同步又提高运行效率,在mapreduce中间的过程引入了barrier(同步障)
在负责同步的同时完成对map的中间结果的统计,包括 a. 对同一个map节点的相同key的value值进行合并,b. 之后将来自不同map的具有相同的key的键值对送到同一个reduce进行处理。
3)在reduce阶段,每个reduce节点得到的是从所有map节点传过来的具有相同的key的键值对。reduce节点对这些键值进行合并。
以词频统计为例。
词频统计就是统计一个单词在所有文本中出现的次数,在hadoop中的事例程序就是wordcount,俗称hadoop编程的"hello world".
因为我们有多个文本,所以可以并行的统计每个文本中单词出现的个数,然后最后进行合计。
所以这个可以很好地体现map,reduce的过程。
可以发现,这张图是上面那张图的进一步细化,主要体现在:
1)Combiner 节点负责完成上面提到的将同一个map中相同的key进行合并,避免重复传输,从而减少传输中的通信开销。
2)Partitioner节点负责将map产生的中间结果进行划分,确保相同的key到达同一个reduce节点.
